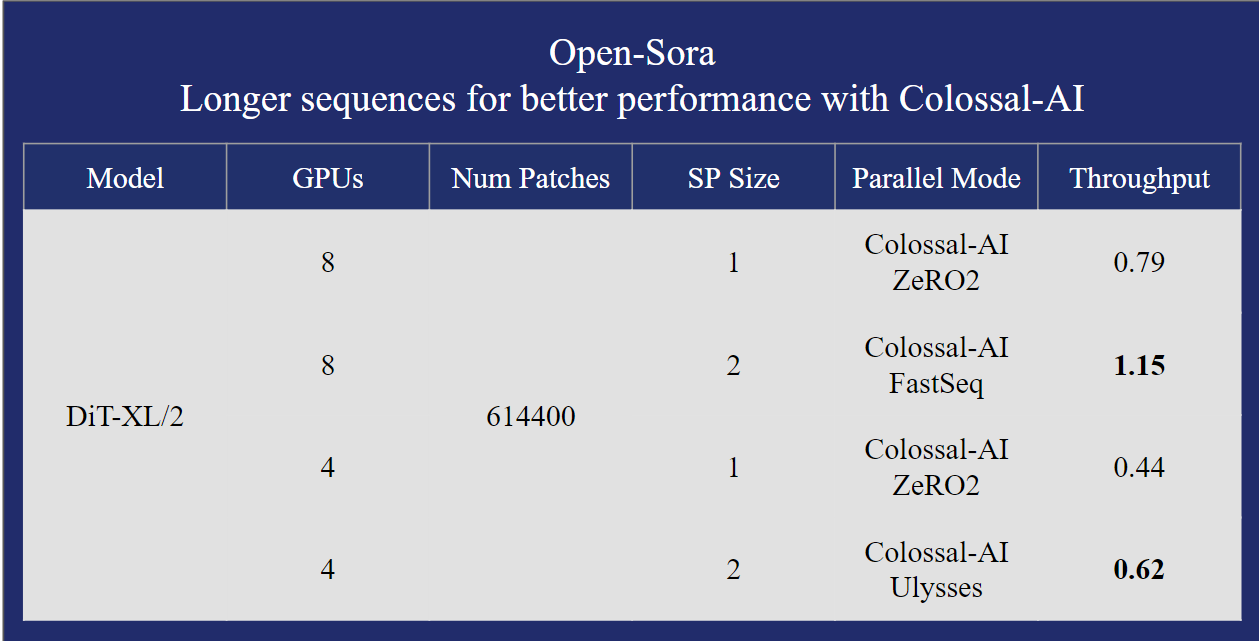
一、说明
如今,当我们谈论深度学习时,通常会将其实现与利用 GPU 来提高性能联系起来。GPU(图形处理单元)最初设计用于加速图像、2D 和 3D 图形的渲染。然而,由于它们能够执行许多并行操作,因此它们的实用性超出了深度学习等应用程序。
二、GPU上启动深度学习
GPU 在深度学习模型中的使用始于 2000 年代中后期,并在 2012 年左右随着 AlexNet 的出现而变得非常流行。 AlexNet 是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 设计的卷积神经网络,于 2012 年赢得了 ImageNet 大规模视觉识别挑战赛 (ILSVRC)。这一胜利标志着一个里程碑,因为它证明了深度神经网络在图像分类和识别方面的有效性。使用 GPU 训练大型模型。
这一突破之后,使用 GPU 进行深度学习模型变得越来越流行,这促成了 PyTorch 和 TensorFlow 等框架的创建。
现在,我们只是.to("cuda")在 PyTorch 中编写将数据发送到 GPU 并期望加速训练。但深度学习算法在实践中如何利用 GPU 的计算性能呢?让我们来看看吧!
神经网络、CNN、RNN 和 Transformer 等深度学习架构基本上是使用矩阵加法、矩阵乘法和将函数应用于矩阵等数学运算来构建的。因此,如果我们找到一种方法来优化这些操作,我们就可以提高深度学习模型的性能。
那么,让我们从简单的开始吧。假设您想要将两个向量C = A + B相加。
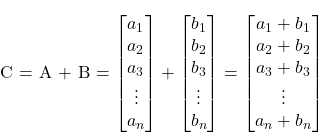
在 C 中的一个简单实现是:
void AddTwoVectors(flaot A[], float B[], float C[]) {
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
}正如您所注意到的,计算机必须迭代向量,在每次迭代中按顺序添加每对元素。但这些操作是相互独立的。第 i对元素的添加不依赖于任何其他对。那么,如果我们可以同时执行这些操作,并行添加所有元素对呢?
一种简单的方法是使用 CPU 多线程来并行运行所有计算。然而,当涉及深度学习模型时,我们正在处理包含数百万个元素的大量向量。一个普通的CPU只能同时处理大约十几个线程。这就是 GPU 发挥作用的时候!现代 GPU 可以同时运行数百万个线程,从而增强了海量向量上的数学运算的性能。
三、GPU 与 CPU 比较
尽管对于单个操作,CPU 计算可能比 GPU 更快,但 GPU 的优势依赖于其并行化能力。其原因是它们的设计目标不同。 CPU 的设计目的是尽可能快地执行一系列操作(线程)(并且只能同时执行数十个操作),而 GPU 的设计目的是并行执行数百万个操作(同时牺牲单个线程的速度)。
为了说明这一点,可以将 CPU 想象成一辆法拉利,将 GPU 想象成总线。如果您的任务是运送一个人,那么法拉利(CPU)是更好的选择。然而,如果您要运送几个人,即使法拉利(CPU)每次行程更快,公共汽车(GPU)也可以一次性运送所有人,比法拉利多次运送路线更快。因此,CPU 更适合处理顺序操作,GPU 更适合处理并行操作。

为了提供更高的并行能力,GPU 设计分配更多的晶体管用于数据处理,而不是数据缓存和流量控制,这与 CPU 分配大量晶体管用于此目的不同,以优化单线程性能和复杂指令执行。
下图展示了CPU vs GPU的芯片资源分布。
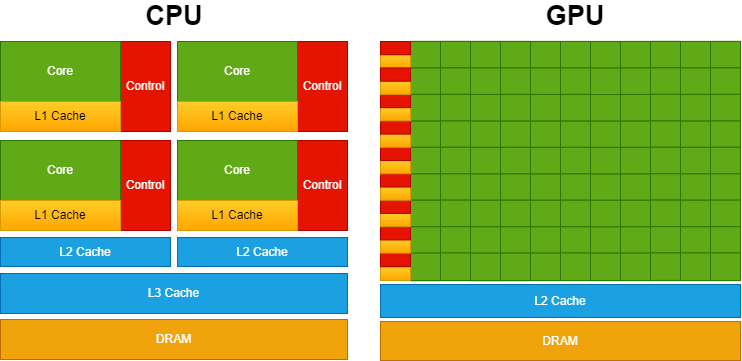
图片由作者提供,灵感来自CUDA C++ 编程指南
CPU 具有强大的内核和更复杂的高速缓存架构(为此分配大量晶体管)。这种设计可以更快地处理顺序操作。另一方面,GPU 优先考虑拥有大量核心以实现更高水平的并行性。
现在我们已经了解了这些基本概念,那么我们如何在实践中利用这种并行计算能力呢?
四、CUDA简介
当您运行某些深度学习模型时,您可能会选择使用一些流行的 Python 库,例如 PyTorch 或 TensorFlow。然而,众所周知,这些库的核心在底层运行 C/C++ 代码。此外,正如我们之前提到的,您可以使用 GPU 来加快处理速度。这就是 CUDA 发挥作用的地方! CUDA 代表统一计算架构,它是 NVIDIA 开发的用于在 GPU 上进行通用处理的平台。因此,虽然游戏引擎使用 DirectX 来处理图形计算,但 CUDA 使开发人员能够将 NVIDIA 的 GPU 计算能力集成到他们的通用软件应用程序中,而不仅仅是图形渲染。
为了实现这一点,CUDA 提供了一个简单的基于 C/C++ 的接口 (CUDA C/C++),该接口允许访问 GPU 的虚拟指令集和特定操作(例如在 CPU 和 GPU 之间移动数据)。
在进一步讨论之前,让我们先了解一些基本的 CUDA 编程概念和术语:
- host:指CPU及其内存;
- device:指GPU及其内存;
- kernel:指在设备(GPU)上执行的函数;
因此,在使用 CUDA 编写的基本代码中,程序在主机( CPU)上运行,将数据发送到设备(GPU) 并启动要在设备(GPU)上执行的内核(函数) 。这些内核由多个线程并行执行。执行后,结果从设备(GPU)传回主机(CPU)。
那么让我们回到两个向量相加的问题:
#include <stdio.h>
void AddTwoVectors(flaot A[], float B[], float C[]) {
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
}
int main() {
...
AddTwoVectors(A, B, C);
...
}在 CUDA C/C++ 中,程序员可以定义称为内核的 C/C++ 函数,这些函数在调用时由 N 个不同的 CUDA 线程并行执行 N 次。
要定义内核,可以使用__global__声明说明符,并且可以使用符号指定执行该内核的 CUDA 线程数<<<...>>>:
#include <stdio.h>
// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
...
// Kernel invocation with N threads
AddTwoVectors<<<1, N>>>(A, B, C);
...
} 每个线程执行内核,并被赋予一个唯一的线程 ID,该 IDthreadIdx可通过内置变量在内核中访问。上面的代码将两个大小为 N 的向量 A 和 B 相加,并将结果存储到向量 C 中。您可以注意到,CUDA 允许我们同时执行所有这些操作,而不是按顺序执行每个成对加法的循环,并行使用 N 个线程。
但在运行这段代码之前,我们需要进行另一次修改。请务必记住,内核函数在设备 (GPU) 内运行。所以它的所有数据都需要存储在设备内存中。您可以使用以下 CUDA 内置函数来完成此操作:
#include <stdio.h>
// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
int N = 1000; // Size of the vectors
float A[N], B[N], C[N]; // Arrays for vectors A, B, and C
...
float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C
// Allocate memory on the device for vectors A, B, and C
cudaMalloc((void **)&d_A, N * sizeof(float));
cudaMalloc((void **)&d_B, N * sizeof(float));
cudaMalloc((void **)&d_C, N * sizeof(float));
// Copy vectors A and B from host to device
cudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);
// Kernel invocation with N threads
AddTwoVectors<<<1, N>>>(d_A, d_B, d_C);
// Copy vector C from device to host
cudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);
}我们需要使用指针,而不是直接将变量 A、B 和 C 传递给内核。在 CUDA 编程中,您不能在内核启动 (<<<...>>>) 中直接使用主机数组(如示例中的 A、B 和 C)。 CUDA 内核在设备内存上操作,因此您需要将设备指针(d_A、d_B 和 d_C)传递给内核以供其操作。
除此之外,我们需要使用 cudaMalloc 在设备上分配内存,并使用 cudaMemcpy 在主机和设备之间复制数据。
现在我们可以添加向量A和B的初始化,并在代码末尾刷新cuda内存。
#include <stdio.h>
// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
int N = 1000; // Size of the vectors
float A[N], B[N], C[N]; // Arrays for vectors A, B, and C
// Initialize vectors A and B
for (int i = 0; i < N; ++i) {
A[i] = 1;
B[i] = 3;
}
float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C
// Allocate memory on the device for vectors A, B, and C
cudaMalloc((void **)&d_A, N * sizeof(float));
cudaMalloc((void **)&d_B, N * sizeof(float));
cudaMalloc((void **)&d_C, N * sizeof(float));
// Copy vectors A and B from host to device
cudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);
// Kernel invocation with N threads
AddTwoVectors<<<1, N>>>(d_A, d_B, d_C);
// Copy vector C from device to host
cudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
} 另外,我们需要添加 cudaDeviceSynchronize();在我们调用内核之后。这是一个用于将主机线程与设备同步的函数。当调用此函数时,主机线程将等待,直到设备上所有先前发出的 CUDA 命令完成后才继续执行。
除此之外,添加一些 CUDA 错误检查也很重要,这样我们就可以识别 GPU 上的错误。如果我们不添加此检查,代码将继续执行主机线程(CPU),并且将很难识别与 CUDA 相关的错误。
两种技术的实现如下:
#include <stdio.h>
// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
int N = 1000; // Size of the vectors
float A[N], B[N], C[N]; // Arrays for vectors A, B, and C
// Initialize vectors A and B
for (int i = 0; i < N; ++i) {
A[i] = 1;
B[i] = 3;
}
float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C
// Allocate memory on the device for vectors A, B, and C
cudaMalloc((void **)&d_A, N * sizeof(float));
cudaMalloc((void **)&d_B, N * sizeof(float));
cudaMalloc((void **)&d_C, N * sizeof(float));
// Copy vectors A and B from host to device
cudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);
// Kernel invocation with N threads
AddTwoVectors<<<1, N>>>(d_A, d_B, d_C);
// Check for error
cudaError_t error = cudaGetLastError();
if(error != cudaSuccess) {
printf("CUDA error: %s\n", cudaGetErrorString(error));
exit(-1);
}
// Waits untill all CUDA threads are executed
cudaDeviceSynchronize();
// Copy vector C from device to host
cudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}要编译并运行 CUDA 代码,您需要确保系统上安装了 CUDA 工具包。然后,您可以使用 NVIDIA CUDA 编译器 nvcc 编译代码。如果您的计算机上没有 GPU,您可以使用 Google Colab。您只需在运行时 → 笔记本设置中选择 GPU,然后将代码保存在 example.cu 文件中并运行:
%%shell
nvcc example.cu -o compiled_example # compile
./compiled_example # run
# you can also run the code with bug detection sanitizer
compute-sanitizer --tool memcheck ./compiled_example 然而,我们的代码仍然没有完全优化。上面的示例使用了大小为 N = 1000 的向量。但是,这是一个很小的数字,无法完全展示 GPU 的并行化能力。此外,在处理深度学习问题时,我们经常处理具有数百万个参数的大量向量。但是,如果我们尝试设置(例如 N = 500000)并<<<1, 500000>>>使用上面的示例运行内核,则会抛出错误。因此,要改进代码并执行此类操作,我们首先需要了解CUDA编程的一个重要概念:线程层次结构。
五、线程层次结构
内核函数的调用是使用符号 完成的<<<number_of_blocks, threads_per_block>>>。因此,在上面的示例中,我们使用 N 个 CUDA 线程运行 1 个块。但是,每个块对其可支持的线程数量都有限制。发生这种情况是因为块内的每个线程都需要位于同一流多处理器核心上,并且必须共享该核心的内存资源。
您可以使用以下代码片段获得此限制:
int device;
cudaDeviceProp props;
cudaGetDevice(&device);
cudaGetDeviceProperties(&props, device);
printf("Maximum threads per block: %d\n", props.maxThreadsPerBlock);在当前的 Colab GPU 上,一个线程块最多可以包含 1024 个线程。因此,我们需要更多的块来执行更多的线程,以便处理示例中的大量向量。此外,块被组织成网格,如下图所示:
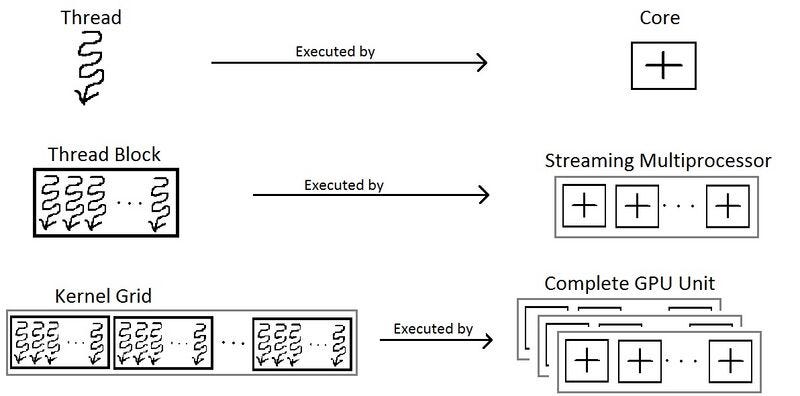
https://handwiki.org/wiki/index.php?curid=1157670(CC BY -SA 3.0)
现在,可以使用以下方式访问线程 ID:
int i = blockIdx.x * blockDim.x + threadIdx.x;所以,我们的脚本变成:
#include <stdio.h>
// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[], int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) // To avoid exceeding array limit
C[i] = A[i] + B[i];
}
int main() {
int N = 500000; // Size of the vectors
int threads_per_block;
int device;
cudaDeviceProp props;
cudaGetDevice(&device);
cudaGetDeviceProperties(&props, device);
threads_per_block = props.maxThreadsPerBlock;
printf("Maximum threads per block: %d\n", threads_per_block); // 1024
float A[N], B[N], C[N]; // Arrays for vectors A, B, and C
// Initialize vectors A and B
for (int i = 0; i < N; ++i) {
A[i] = 1;
B[i] = 3;
}
float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C
// Allocate memory on the device for vectors A, B, and C
cudaMalloc((void **)&d_A, N * sizeof(float));
cudaMalloc((void **)&d_B, N * sizeof(float));
cudaMalloc((void **)&d_C, N * sizeof(float));
// Copy vectors A and B from host to device
cudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);
// Kernel invocation with multiple blocks and threads_per_block threads per block
int number_of_blocks = (N + threads_per_block - 1) / threads_per_block;
AddTwoVectors<<<number_of_blocks, threads_per_block>>>(d_A, d_B, d_C, N);
// Check for error
cudaError_t error = cudaGetLastError();
if (error != cudaSuccess) {
printf("CUDA error: %s\n", cudaGetErrorString(error));
exit(-1);
}
// Wait until all CUDA threads are executed
cudaDeviceSynchronize();
// Copy vector C from device to host
cudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}六、性能比较
下面对不同向量大小的两个向量相加运算的 CPU 和 GPU 计算进行了比较。
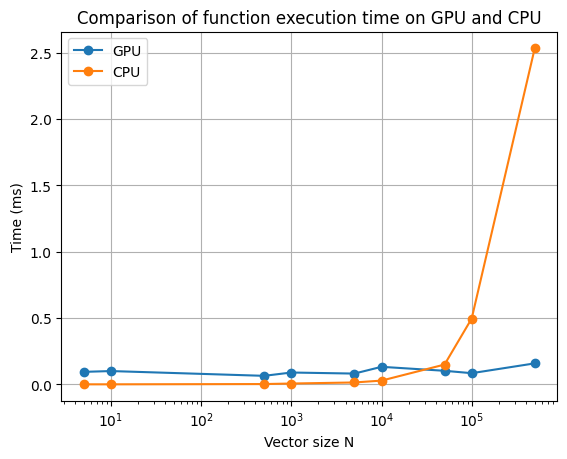
图片由作者提供
正如我们所看到的,GPU 处理的优势只有在向量大小 N 较大时才变得明显。另外,请记住,这次比较仅考虑内核/函数的执行。它没有考虑在主机和设备之间复制数据的时间,尽管在大多数情况下这可能并不重要,但在我们的情况下相对相当可观,因为我们只执行简单的加法操作。因此,重要的是要记住,GPU 计算仅在处理高度计算密集型且高度并行化的计算时才显示出其优势。
七、多维线程
好的,现在我们知道如何提高简单数组操作的性能。但在处理深度学习模型时,我们需要处理矩阵和张量运算。在前面的示例中,我们仅使用具有 N 个线程的一维块。但是,也可以执行多维线程块(最多 3 维)。因此,为了方便起见,如果需要运行矩阵运算,可以运行 NxM 线程的线程块。在这种情况下,您可以获得矩阵行列索引为row = threadIdx.x, col = threadIdx.y。另外,为了方便起见,您可以使用dim3变量类型来定义number_of_blocks和threads_per_block.
下面的示例说明了如何添加两个矩阵。
#include <stdio.h>
// Kernel definition
__global__ void AddTwoMatrices(float A[N][N], float B[N][N], float C[N][N]) {
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main() {
...
// Kernel invocation with 1 block of NxN threads
dim3 threads_per_block(N, N);
AddTwoMatrices<<<1, threads_per_block>>>(A, B, C);
...
}您还可以扩展此示例以处理多个块:
#include <stdio.h>
// Kernel definition
__global__ void AddTwoMatrices(float A[N][N], float B[N][N], float C[N][N]) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N) {
C[i][j] = A[i][j] + B[i][j];
}
}
int main() {
...
// Kernel invocation with 1 block of NxN threads
dim3 threads_per_block(32, 32);
dim3 number_of_blocks((N + threads_per_block.x - 1) ∕ threads_per_block.x, (N + threads_per_block.y - 1) ∕ threads_per_block.y);
AddTwoMatrices<<<number_of_blocks, threads_per_block>>>(A, B, C);
...
}您还可以使用相同的想法扩展此示例以处理 3 维操作。
现在您知道了如何操作多维数据,还有另一个重要且简单的概念需要学习:如何在内核中调用函数。基本上,这只需使用__device__声明说明符即可完成。这定义了设备(GPU)可以直接调用的函数。因此,它们只能从__global__另一个__device__函数调用。下面的示例将 sigmoid 运算应用于向量(深度学习模型上非常常见的运算)。
#include <math.h>
// Sigmoid function
__device__ float sigmoid(float x) {
return 1 / (1 + expf(-x));
}
// Kernel definition for applying sigmoid function to a vector
__global__ void sigmoidActivation(float input[], float output[]) {
int i = threadIdx.x;
output[i] = sigmoid(input[i]);
}现在您已经了解了 CUDA 编程的基本重要概念,您可以开始创建 CUDA 内核了。就深度学习模型而言,它们基本上是一堆矩阵和张量运算,例如求和、乘法、卷积、归一化等。例如,一个简单的矩阵乘法算法可以并行化如下:
![]()
// GPU version
__global__ void matMul(float A[M][N], float B[N][P], float C[M][P]) {
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
if (row < M && col < P) {
float C_value = 0;
for (int i = 0; i < N; i++) {
C_value += A[row][i] * B[i][col];
}
C[row][col] = C_value;
}
}现在将其与下面两个矩阵乘法的普通 CPU 实现进行比较:
// CPU version
void matMul(float A[M][N], float B[N][P], float C[M][P]) {
for (int row = 0; row < M; row++) {
for (int col = 0; col < P; col++) {
float C_value = 0;
for (int i = 0; i < N; i++) {
C_value += A[row][i] * B[i][col];
}
C[row][col] = C_value;
}
}
}您可以注意到,在 GPU 版本上,我们的循环更少,从而可以更快地处理操作。下面是CPU和GPU在NxN矩阵乘法上的性能比较:图片由作者提供
正如您所观察到的,随着矩阵大小的增加,矩阵乘法运算的 GPU 处理性能提升甚至更高。
现在,考虑一个基本的神经网络,它主要涉及y = σ(W x + b ) 操作,如下所示:
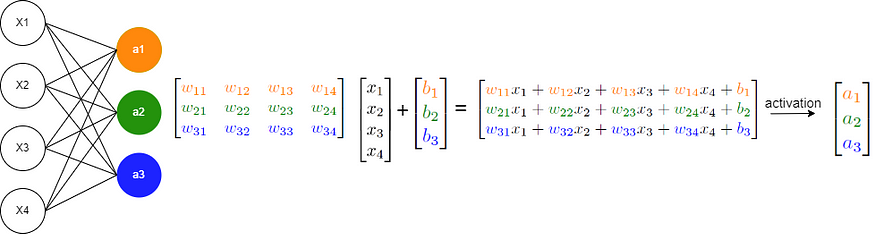
图片由作者提供
这些操作主要包括矩阵乘法、矩阵加法以及将函数应用于数组,所有这些操作您都已经熟悉了并行化技术。因此,您现在能够从头开始实现在 GPU 上运行的自己的神经网络!
八、结论
在这篇文章中,我们介绍了有关 GPU 处理以增强深度学习模型性能的介绍性概念。然而,还需要指出的是,您所看到的概念只是基础知识,还有很多东西需要学习。 PyTorch 和 Tensorflow 等库实现的优化技术涉及其他更复杂的概念,例如优化内存访问、批量操作等(它们利用构建在 CUDA 之上的库,例如 cuBLAS 和 cuDNN)。不过,我希望这篇文章能够帮助您了解.to("cuda")在 GPU 上编写和执行深度学习模型时幕后发生的事情。
在以后的文章中,我将尝试引入有关 CUDA 编程的更复杂的概念。请在评论中告诉我您的想法或您希望我接下来写什么!非常感谢您的阅读!